Locally Aware Piecewise Transformation Fields
for 3D Human Mesh Registration
Abstract
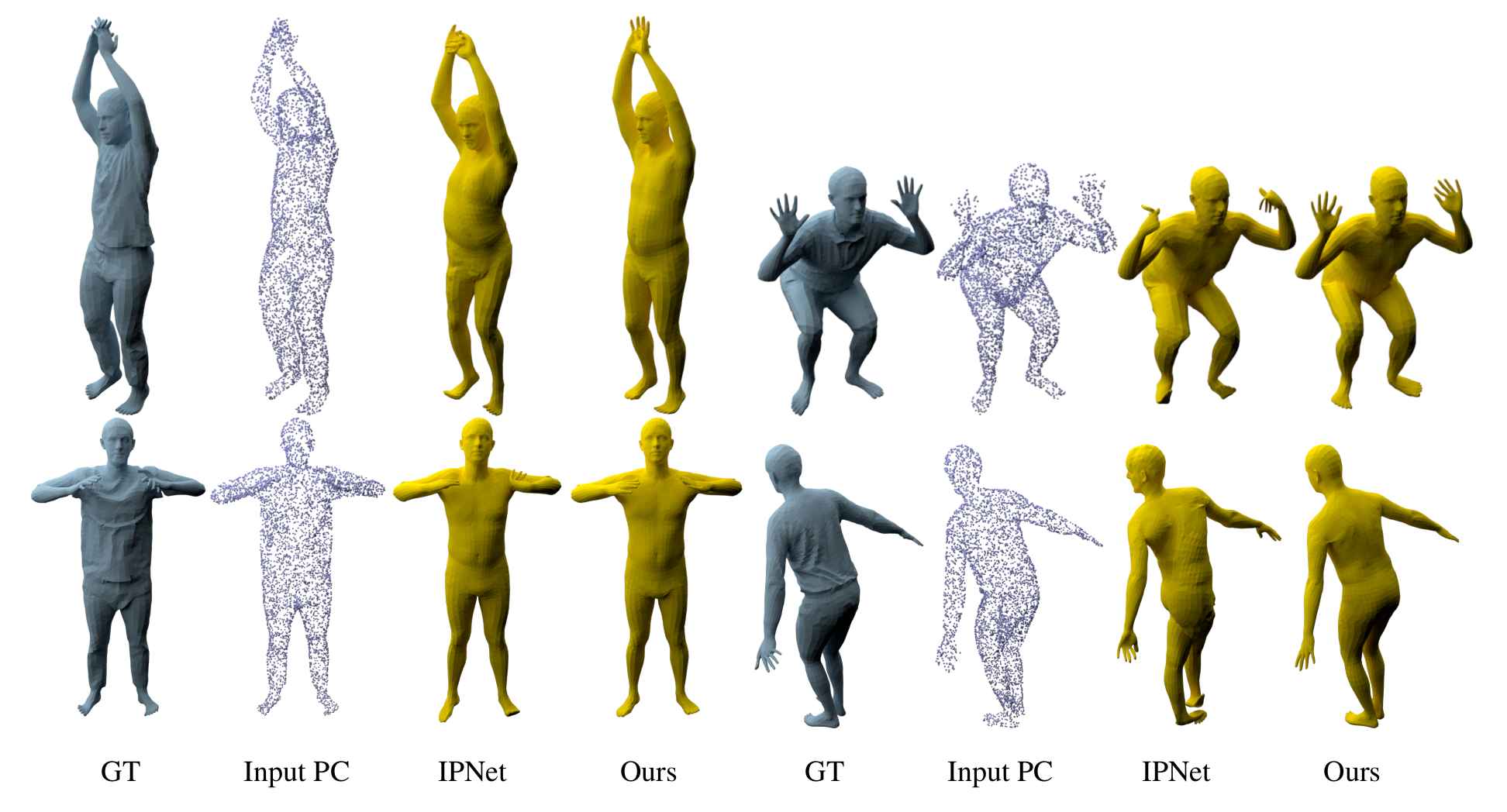
Registering point clouds of dressed humans to parametric human models is a challenging task in computer vision. Traditional approaches often rely on heavily engineered pipelines that require accurate manual initialization of human poses and tedious post-processing. More recently, learning-based methods are proposed in hope to automate this process. We observe that pose initialization is key to accurate registration but existing methods often fail to provide accurate pose initialization. One major obstacle is that, despite recent effort on rotation representation learning in neural networks, regressing joint rotations from point clouds or images of humans is still very challenging. To this end, we propose novel piecewise transformation fields (PTF), a set of functions that learn 3D translation vectors to map any query point in posed space to its correspond position in rest-pose space. We combine PTF with multi-class occupancy networks, obtaining a novel learning-based framework that learns to simultaneously predict shape and per-point correspondences between the posed space and the canonical space for clothed human. Our key insight is that the translation vector for each query point can be effectively estimated using the point-aligned local features; consequently, rigid per bone transformations and joint rotations can be obtained efficiently via a least-square fitting given the estimated point correspondences, circumventing the challenging task of directly regressing joint rotations from neural networks. Furthermore, the proposed PTF facilitates canonicalized occupancy estimation, which greatly improves generalization capability and results in more accurate surface reconstruction with only half of the parameters compared with the state-of-the-art. Both qualitative and quantitative studies show that fitting parametric models with poses initialized by our network results in much better registration quality, especially for extreme poses.
Additional Single-View Results


PTF also works on single-view depth inputs. Please check out our latest code-release for implementation and pre-trained model.
Videos
Citation
@inproceedings{PTF:CVPR:2021,
author = {Shaofei Wang and Andreas Geiger and Siyu Tang},
title = {Locally Aware Piecewise Transformation Fields for 3D Human Mesh Registration},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}